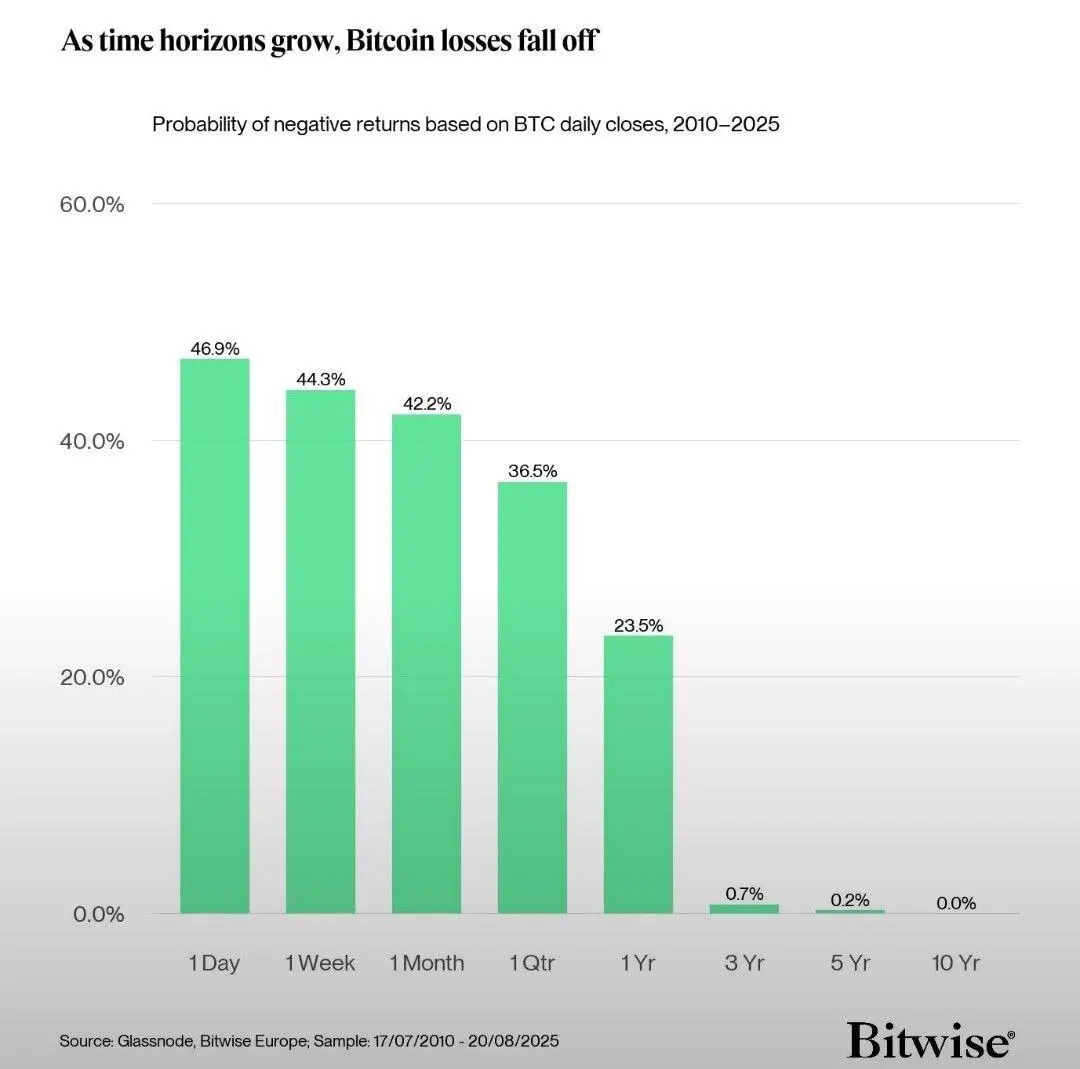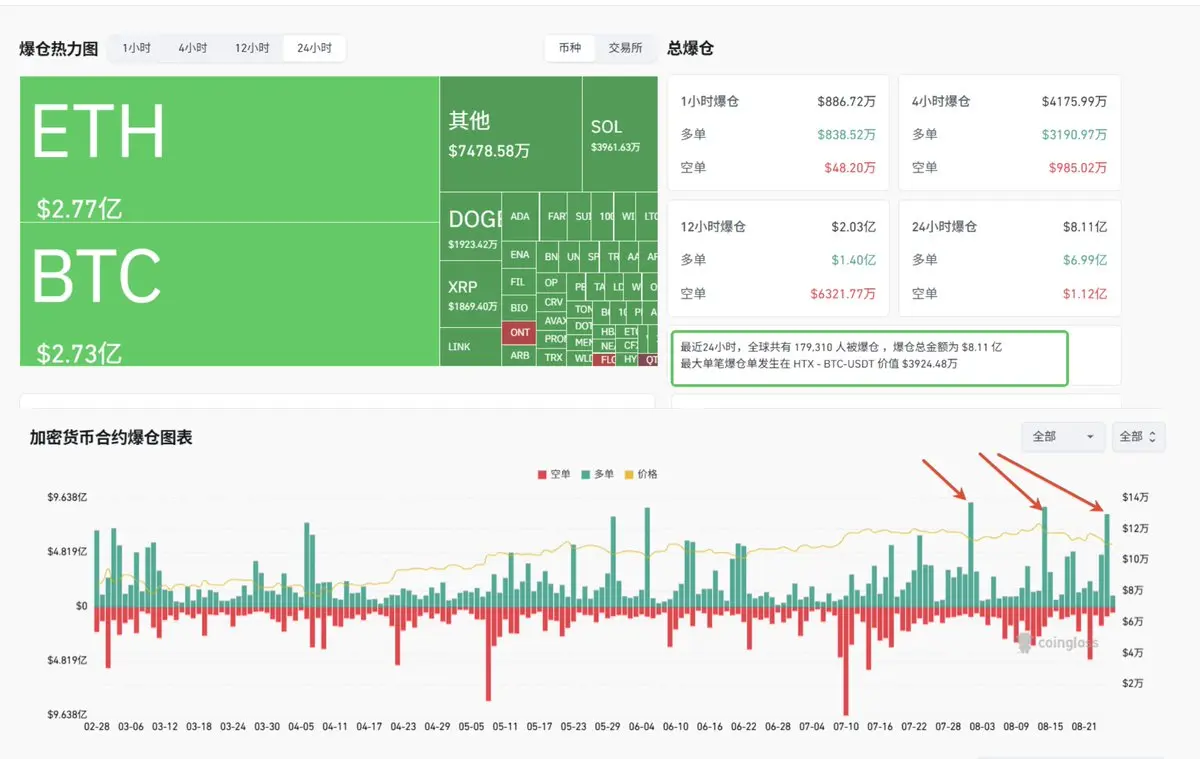
Chính là phải liên tục nhớ lại trải nghiệm thành công/thất bại, giống như cơ chế thưởng/phạt trong đào tạo AI, có một hàm liên tục điều chỉnh các tham số.
Như vậy mới có thể điều chỉnh đến kết luận tương đối khách quan và lý tính khi bản thân tạo ra "ảo giác" vào lần sau.
Đây chính là hiệu quả đào tạo do "kiếm tiền" "mất tiền" "kinh nghiệm" mang lại.
Xem bản gốcNhư vậy mới có thể điều chỉnh đến kết luận tương đối khách quan và lý tính khi bản thân tạo ra "ảo giác" vào lần sau.
Đây chính là hiệu quả đào tạo do "kiếm tiền" "mất tiền" "kinh nghiệm" mang lại.